MCU大廠的新战場
衆多趨勢表明,AI,不再只是“雲端的特權”,而是正快速成爲“終端的標配”。而在這一發展趨勢下,微控制器(MCU)大廠似乎早已嗅到其中端倪。
在AI芯片領域,曾長期由GPU和專用ASIC主導,但這些解決方案往往功耗高昂、靈活性不足,難以適應電池供電、尺寸受限的終端設備。相比之下,MCU具備天然的低功耗、可定制性強的優勢。當AI的浪潮從數據中心湧向邊緣設備,整個MCU行業也隨之進入轉型的風口。MCU,這一曾經以成本、功耗和實時性著稱的嵌入式主力軍,如今正承載着越來越多智能化的野心。
過去幾年,MCU廠商們主要通過在軟件工具包(SDK)中添加AI功能來提升現有產品,但自去年开始,硬件層面的集成已成爲行業發展的主流趨勢。尤其是MCU與NPU(神經處理單元)的集成,標志着MCU硬件在AI應用中的潛力被徹底釋放。邊緣智能時代的MCU競爭,已然拉开帷幕。
爲什么AI一定要走到終端?
一句話總結:用戶需求逼着AI“下沉”。
試想一下,我們在用掃地機器人、可穿戴設備、安防攝像頭的時候,都希望設備能“自己做決定”,而不是每次都把數據傳到雲端再等結果。這不僅慢,還容易涉及隱私和網絡穩定性問題。
根據Gartner的數據,AI芯片市場從2019年的120億美元預計將在2024年增長到430億美元。而其中一個重要驅動力,就是邊緣AI。
然而,要想把AI部署在小巧的嵌入式設備中,最大的挑战是兩個字:限制。功耗限制、算力限制、內存限制……傳統MCU根本帶不動復雜的神經網絡模型。而如果硬塞一個GPU上去,又會把整個系統的成本和功耗推到不可接受的水平。
因此,“能跑AI的低功耗MCU”成了邊緣智能的關鍵解法。無論如何,只有當邊緣人工智能在所有嵌入式系統上都能更輕松地訪問時,它才會變得無處不在。
在此背景下,MCU市場的領導者們已經不滿足於僅在軟件工具包中增加機器學習功能,而是开始在硬件上集成NPU。這一轉變標志着一個全新時代的來臨。
六大MCU巨頭的AI战術
包括ST、NXP、英飛凌、瑞薩、芯科科技在內的MCU巨頭都已經有了實打實的AI MCU。廠商的技術選擇,與其擅長的細分市場高度契合——從消費級到工業級、從車載到低功耗IoT,都能找到對應的“拳頭產品”。
1. STMicroelectronics:從軟件突圍到硬核自主
ST很早就看到了MCU上跑AI的潛力。早在2016年就开發了自家的神經網絡加速器Neural-ART,並在2019年推出了知名的STM32Cube.AI工具,讓开發者可以將訓練好的AI模型轉換成可運行在STM32 MCU上的代碼。
STM32N6是ST最新推出、功能最強大的STM32產品,也是首款搭載Neural-ART加速器的STM32產品。它也是ST的首款 Cortex-M55 MCU,也是業內少數幾款運行頻率高達 800 MHz 的 MCU 之一。此外,STM32N6 擁有 4.2 MB 的內置 RAM,是 STM32 中最大的內置 RAM。它也是ST首款搭載NeoChrom GPU和 H.264 硬件編碼器的產品。
STM32N6搭載自研的Neural-ART加速器是一款定制的神經處理單元 (NPU),擁有近 300 個可配置乘法累加單元和兩條64位 AXI 內存總线,吞吐量高達600 GOPS,讓原本需要加速微處理器的機器學習應用現在可以在 MCU上運行。這一突破性的架構不僅允許每個時鐘周期執行更多操作,並優化數據流以避免瓶頸,而且還針對功耗進行了優化,實現了3 TOPS/W。Neural-ART加速器在發布時就支持比業界普遍水平更多的AI算子。全新 STM32N6已兼容TensorFlow Lite、Keras和ONNX等衆多AI算子,未來還能再繼續增加算子數量,不過僅目前支持的ONNX格式就意味着數據科學家可以將STM32N6用於最廣泛的AI應用。
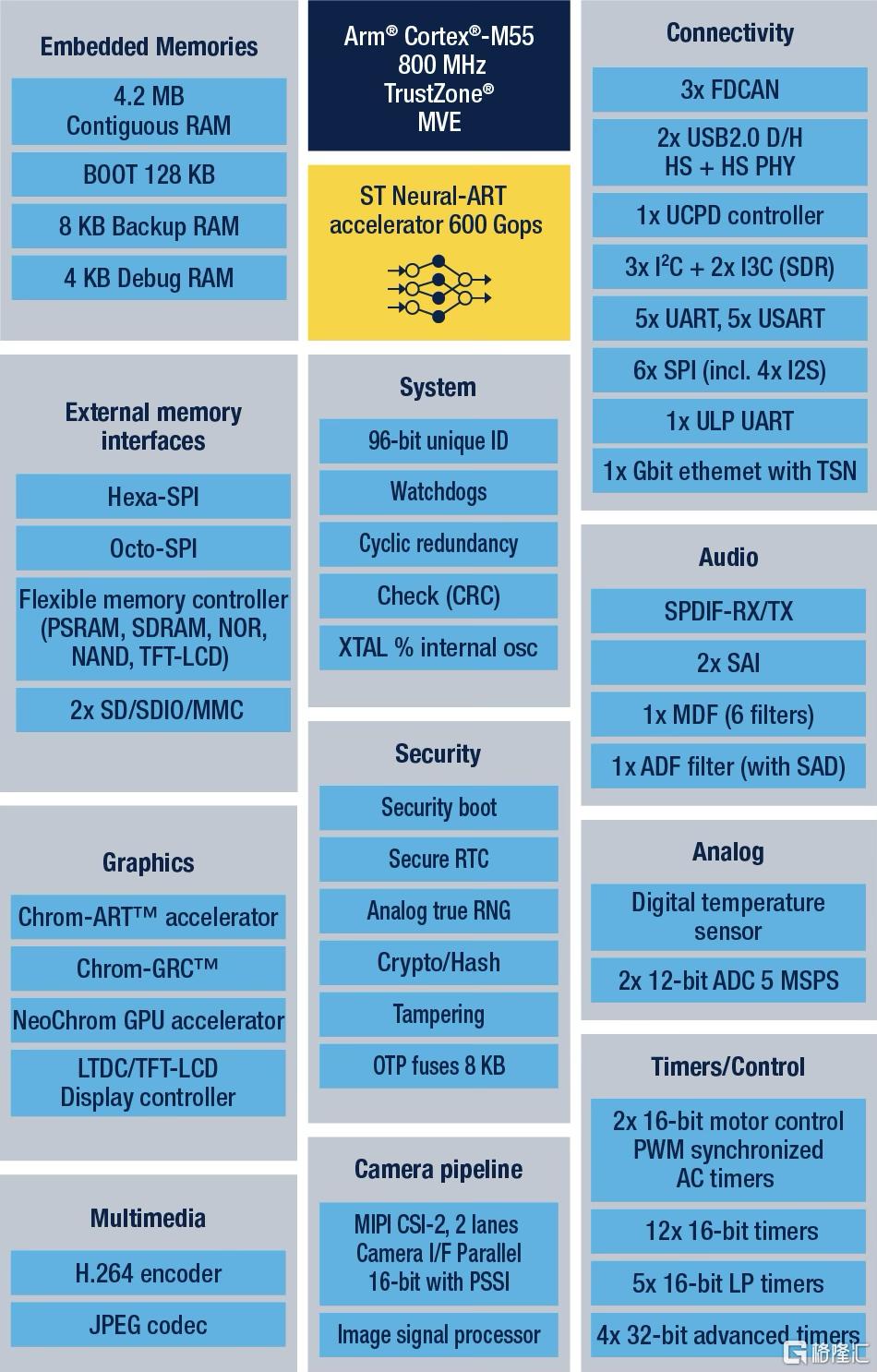
STM32N6框圖
ST憑借自研NPU和成熟生態體系,把“AI跑在MCU上”變成了一件真正可行、可商用的事情。意法半導體微控制器、數字IC和射頻產品部總裁Remi El-Ouazzane表示,STM32N6有望成爲STM32產品线中營收最快突破1億美元的產品之一。
2. NXP:雙线並進,汽車與消費共振
與ST類似,恩智浦早在2018年也推出了機器學習軟件eIQ軟件,該軟件能夠在恩智浦EdgeVerse微控制器和微處理器(包括i.MX RT跨界MCU和i.MX系列應用處理器)上使用。
此前,NXP主要依賴第三方IP(如Arm的Ethos系列)來實現AI加速功能。然而,隨着AI推理需求的多樣化和快速發展,爲了更好地滿足市場需求並增強產品競爭力。據NXP的AI战略負責人Ali Ors指出,AI工作負載的快速演進和模型的多樣性使得依賴第三方IP變得不再靈活,爲了更好地支持客戶,特別是在產品部署後仍能提供長期支持,NXP決定开發自有的NPU架構。2023年1月,NXP正式推出了eIQ Neutron NPU,eIQ Neutron NPU支持多種神經網絡類型,例如CNN、RNN、TCN和Transformer網絡等。
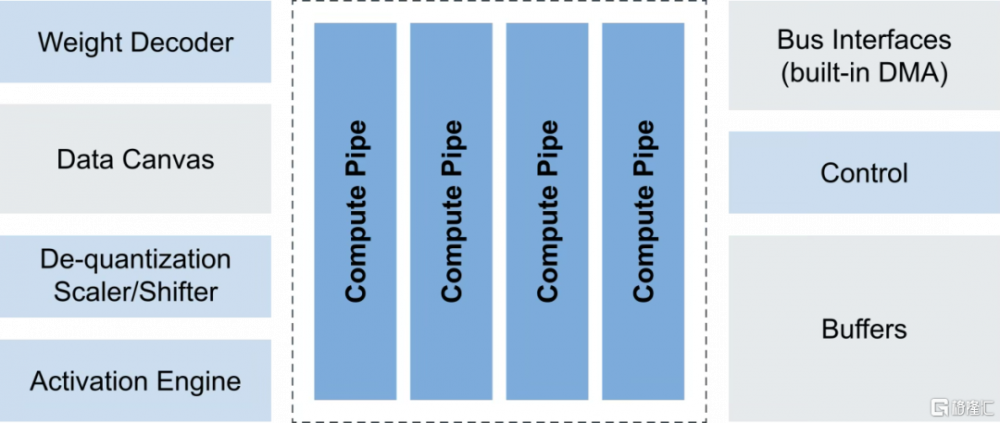
NXP eIQ Neutron NPU系統框圖
目前NXP已在兩款MCU中都集成上了NPU:1)在i.MX RT700跨界MCU中集成eIQ Neutron NPU,供高達172倍的AI推理加速,並將每次推理的能耗降低至原來的1/119,支持語音識別、HMI交互、智能家居等場景;2)在最新的S32K5汽車MCU中也引入了NPU,這是業界首款集成嵌入式MRAM和NPU的汽車級16nm MCU。
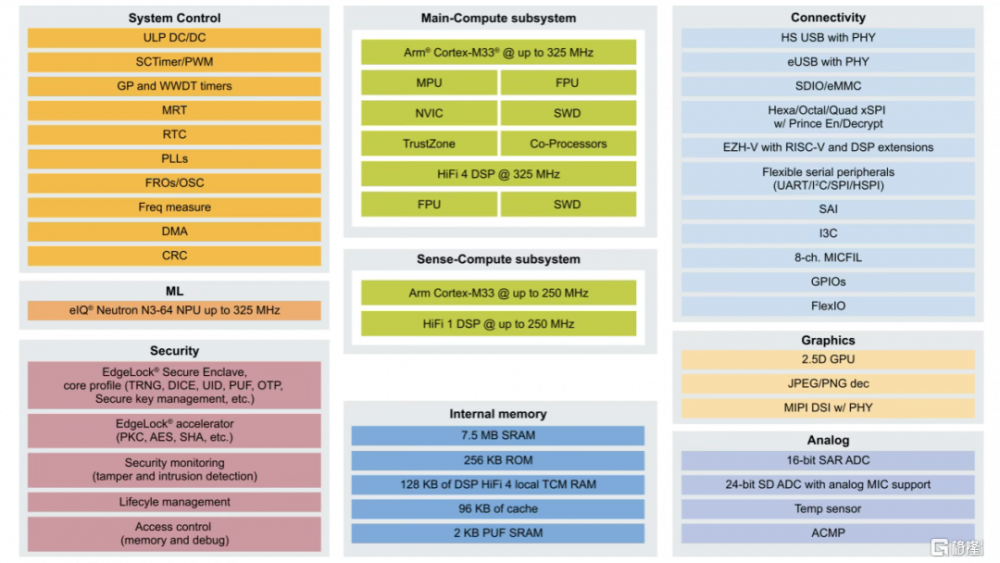
i.MX RT700 跨界 MCU
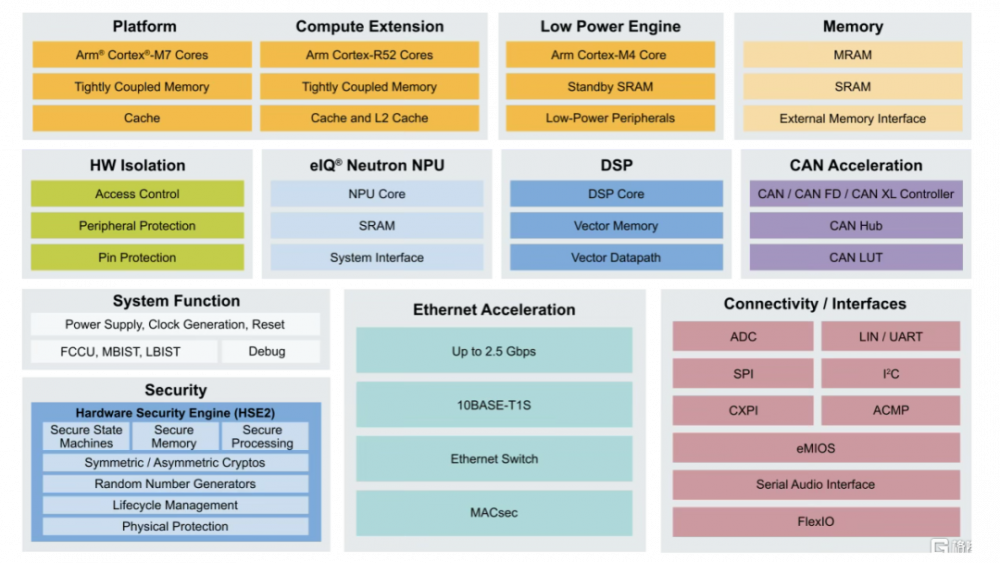
S32K5汽車微控制器
爲了配合eIQ Neutron NPU的使用,NXP在eIQ軟件中新增了對eIQ Neutron NPU的支持,支持开發各種類型的神經網絡,包括CNN、RNN、Transformer等,非常靈活。
3. 英飛凌:借力Arm生態,快步切入AI賽道
英飛凌並未押注自研NPU,而是選擇與Arm Ethos-U55綁定。其PSOC Edge系列借助Arm Cortex-M55 + Ethos-U55的組合,加之與NVIDIA TAO工具鏈的集成,在高精度視覺AI和低功耗設計之間取得了不錯的平衡。
英飛凌重在降低AI开發門檻,走“通用平台 + 快速集成”路线,節省研發時間,是入門邊緣AI的務實選擇。但缺點是差異化有限,長期競爭力依賴生態深度。
4. TI:實時控制+AI並舉
TI打出的牌更偏工業和汽車實時控制方向,其TMS320F28P55x C2000 MCU系列是首個內建NPU的實時控制MCU。NPU不僅提升故障檢測准確率至99%以上,還能降低延遲5~10倍。TI的C2000一直在嵌入式市場數十年經久不衰,與電源、工業驅動緊密耦合,將AI作爲系統智能提升的“內生力”。
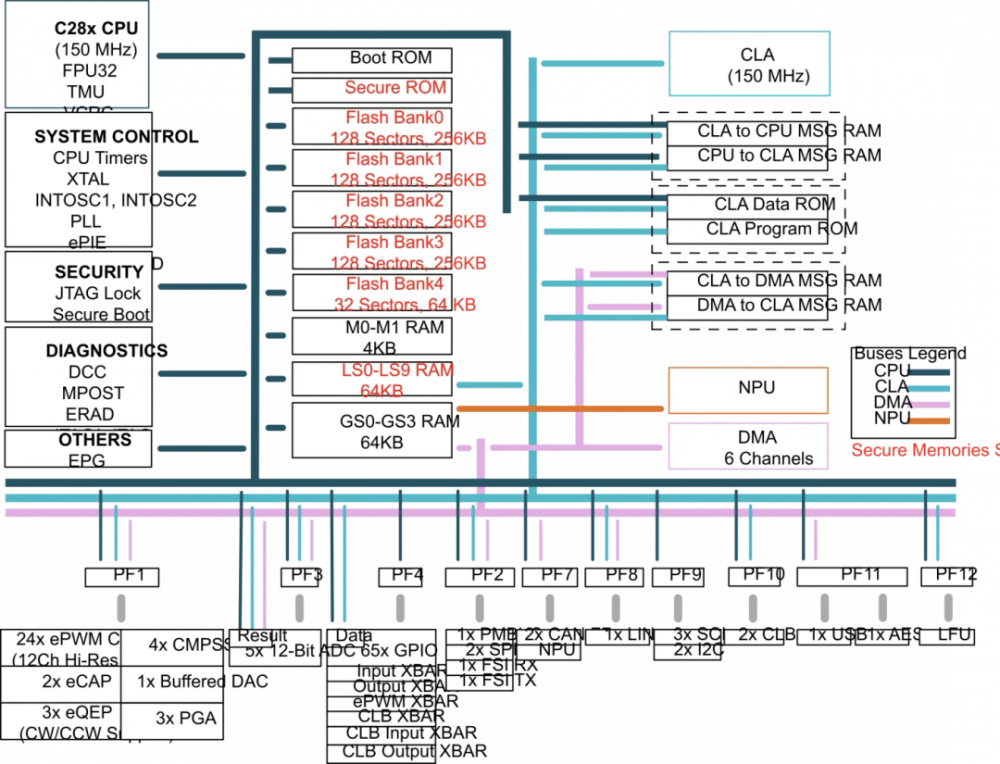
TMS320F28P550SJ系統框圖
5. 瑞薩電子:走無NPU的極致優化路线
瑞薩目前尚未推出集成NPU的MCU,但其RA8系列MCU使用了Cortex-M85 + Helium技術,在不依賴NPU的前提下,也能跑基礎的AI模型。
這種“用架構挖潛力”的策略降低了系統復雜度與成本,適用於無需大規模神經網絡的場景,如語音識別、預測性維護等。瑞薩用軟硬協同優化替代NPU,“無NPU勝有NPU”,打出的是“高性價比”的技術路线。
6. 芯科科技:專注物聯網的AI能效王者
芯科科技(Silicon Labs)的xG26系列SoC/MCU定位明確:爲無线物聯網打造極致AI能效。其矩陣矢量AI加速器可實現8倍速提升、1/6功耗,特別適合電池供電設備(如傳感器、智能門鎖)中以AI喚醒替代長時間運行的場景。Silicon Labs主打小而美的“低功耗AI”,在IoT中找到專屬打法,是垂直領域差異化的典範。
國內MCU廠商也不甘示弱
在MCU這個賽道,國內玩家頗多,也很卷,MCU+AI這股風自然也在國內刮起。
國芯科技推出了首顆端側AI芯片CCR4001S,並與美電科技聯合推出AI傳感器模組,實現了圖像識別、語音識別等功能的本地處理。該芯片採用了自研的NPU架構,支持高效的AI推理,適用於智能家居、安防監控等場景。
CCR4001S端側AI MCU是國芯科技首款基於自主RISC-V CRV4H內核的邊緣AI芯片,內置0.3 TOPS@INT8的NPU加速子系統,支持TensorFlow、PyTorch、TensorFlow Lite、Caffe、ONNX等主流框架。該芯片已通過工業級內部測試,具備高可靠性,可廣泛應用於工業電機控制、能耗優化、AI傳感器、產品缺陷檢測與預測性維護等場景。國芯科技與美電科技聯合推出的AI傳感器模組,利用CCR4001S在本地完成圖像和語音識別,實現無需雲端即可部署的端側智能化解決方案。
兆易創新GD32G5系列MCU也已具備一定的AI算法處理能力,它以Arm Cortex-M33高性能內核爲基礎,高達216 MHz的主頻配合內置DSP硬件加速器、單精度浮點單元(FPU)和硬件三角函數加速器(TMU),可支持10類數學函數運算;同時集成濾波器(FAC)與快速傅裏葉變換(FFT)加速單元,使得該系列在最高主頻下可達316 DMIPS,CoreMark分數694。兆易創新表示,未來將進一步強化硬件AI加速能力,全面布局端側智能市場。
澎湃微推出了集成 TinyML能力的32位MCU,憑借片上神經網絡加速和標准電機控制外設,可在單芯片上實現離线語音識別與電機驅動控制,適用於智能家電、工業設備和物聯網傳感節點等場景。通過本地小模型推理,可大幅降低對雲端的依賴,提升響應速度並節省成本
借助自研架構、完整生態和靈活採購優勢,國內MCU廠商正以“快、真、穩”的姿態迎頭趕上。他們不僅在產品性能指標上與國際巨頭同場競技,更通過更貼近應用的本地化解決方案,爲下遊客戶提供了更具成本效益和开發效率的AI邊緣計算選擇。未來,隨着更多創新迭代的落地,國內MCU+AI賽道的競爭必將更加激烈,也將帶來更多意想不到的驚喜。
MCU x AI,未來的趨勢
MCUxAI,趨勢已經不可避免。過去,AI功能常被視爲MCU的增值插件;未來,AI將成爲MCU的內置能力。從安全監測到狀態識別,再到節能智能調度,各類嵌入式應用都將默認搭載AI加速單元,MCU若無AI引擎便難以在市場中立足。
一塊NPU芯片的算力固然重要,但真正決定其生命周期的,是完整的生態體系——從模型轉換工具、推理框架,到量化精度與算子支持。擁有成熟軟硬件配套的ST、NXP等廠商,將在行業標准與客戶粘性上持續領先。
從市場層面來看,不同細分市場對AI MCU有着截然不同的優先訴求。消費電子追求廉價、易部署、快速迭代;汽車與工業則強調功能安全、穩定可靠、超低時延;物聯網要求超低功耗、高度集成。MCU大廠圍繞這些需求,正沿着自研NPU、授權IP、軟件加速等多條技術路线並行布局。
隨着AI加速單元日臻成熟,多種嵌入式設計將以“混合CPU + NPU”架構取代掉一些傳統CPU + MPU方案。此舉不僅重塑產品定義,還將對半導體供應鏈、IP授權模式和產業分工帶來深遠影響——真正掀起新一輪的技術與商業革命。
結語
MCU上的AI之战,既是技術創新的前沿,也是產業模式重塑的風口。集成NPU的MCU,正從技術探索邁入商業化加速階段。短期看,各家在架構與性能上各擅勝場;長期看,真正能讓AI“無感”融入千千萬萬設備的,是軟硬一體的生態體驗與垂直場景的精准落地。隨着時間的推移,所有用於終端ML應用的MCU都將變成混合CPU/NPU設備。這與過去幾十年MCU領域的其他基本趨勢一樣不可避免,例如轉向基於閃存的MCU,以及幾乎所有MCU都集成USB連接。
標題:MCU大廠的新战場
地址:https://www.iknowplus.com/post/221498.html